class: title-slide, center, middle # Data Reshaping with {tidyr} --- # What is "tidy" data? There are three interrelated rules which make a dataset tidy: -- 1. Each variable must have its own column. 1. Each observation must have its own row. 1. Each value must have its own cell. -- <img src="images/tidy_data.png" width="2560" /> .footnote[Source: [R for Data Science](https://r4ds.had.co.nz/tidy-data.html#tidy-data-1)] --- # What is "tidy" data? <img src="images/tidy_data_2.png" width="2560" /> .footnote[Source: [R for Data Science](https://r4ds.had.co.nz/tidy-data.html#tidy-data-1)] --- # What is "tidy" data? <img src="images/tidy_data_3.png" width="2560" /> .footnote[Source: [R for Data Science](https://r4ds.had.co.nz/tidy-data.html#tidy-data-1)] --- # What is "tidy" data? <img src="images/tidy_data_4.png" width="1955" /> .footnote[Source: [R for Data Science](https://r4ds.had.co.nz/tidy-data.html#tidy-data-1)] --- # What is "tidy" data? <img src="images/tidy_data_5.png" width="2311" /> .footnote[Source: [R for Data Science](https://r4ds.had.co.nz/tidy-data.html#tidy-data-1)] --- class: inverse, center, middle # Pivoting --- background-image: url(images/hex/tidyr.png) background-position: 90% 5% background-size: 10% # Pivoting Most of the data you encounter in the real world will, unfortunately, not be in tidy format. -- This means you will need to reshape your data into a format that is tidy. -- *** This is where the `{tidyr}` package comes in. It contains two crucial functions that you can use to reshape your data: -- .pull-left[ `pivot_longer()` "lengthens" data, increasing the number of rows and decreasing the number of columns. ] .pull-right[ `pivot_wider()` "widens" data, increasing the number of columns and decreasing the number of rows. ] *** ***Note:*** The old versions of these functions were called `gather()` and `spread()`. --- background-image: url(images/hex/tidyr.png) background-position: 90% 5% background-size: 10% # Pivoting 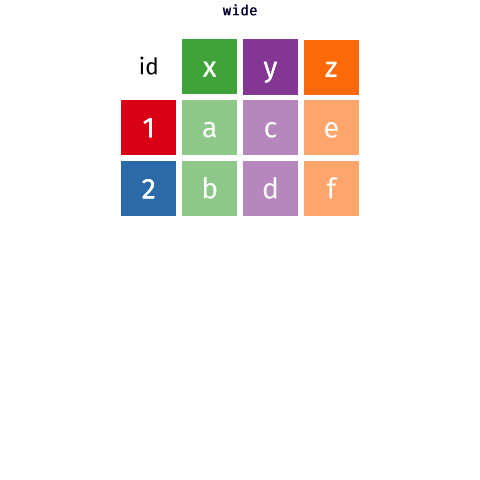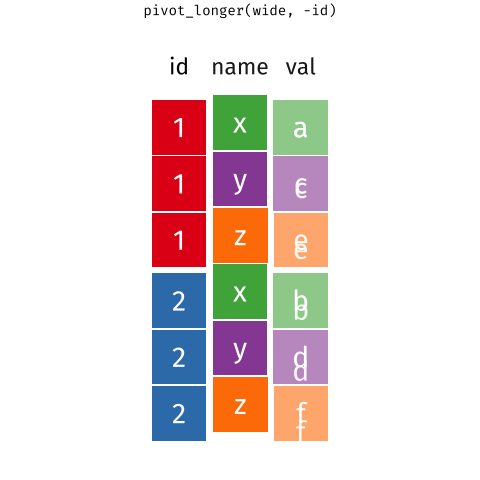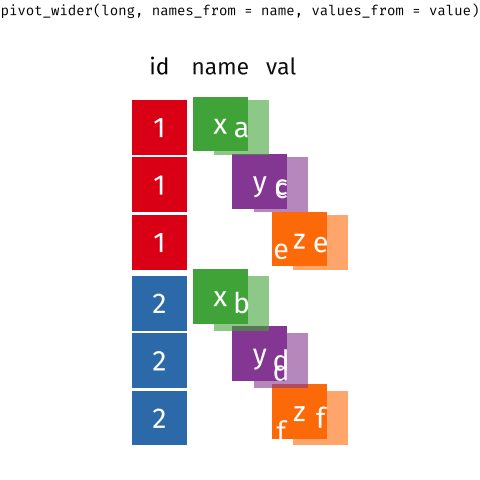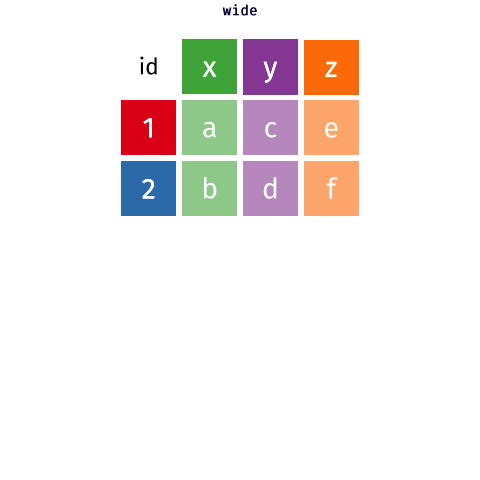<!-- --> .footnote[Source: [Mara Averick](https://twitter.com/dataandme/status/1175913657907253254?s=20) and [Garrick Aden-Buie](https://github.com/gadenbuie/tidyexplain)] --- # Example data Our example data is the total student enrollment for the University of Oregon, Oregon State University, and Portland State University between 2020 and 2021. -- *** .pull-left[ We need to reshape this data to a longer format ```r enrollment ``` ``` ## # A tibble: 3 x 3 ## university `2020` `2021` ## <chr> <dbl> <dbl> ## 1 UO 21800 22298 ## 2 OSU 33359 34108 ## 3 PSU 26012 23181 ``` ] -- .pull-right[ + The column names `2020` and `2021` are not variables in our data, instead they represent values of the year variable + The values in the `2020` and `2021` columns represent values of the `enrollment` variable + Each row represents two observations, not one ] --- background-image: url(images/hex/tidyr.png) background-position: 90% 5% background-size: 10% # `pivot_longer()` ```r enrollment ``` ``` ## # A tibble: 3 x 3 ## university `2020` `2021` ## <chr> <dbl> <dbl> ## 1 UO 21800 22298 ## 2 OSU 33359 34108 ## 3 PSU 26012 23181 ``` -- *** We need 3 pieces of information to reshape (pivot) this data into a tidy format -- + The set of columns in `enrollment` whose names are actually values, not variables. In this example, those are the columns `2020` and `2021`. -- + The name of the variable to move the column names to. Here it is `year`. -- + The name of the variable to move the column values to. Here it’s `enrollment`. --- background-image: url(images/hex/tidyr.png) background-position: 90% 5% background-size: 10% # `pivot_longer()` .panelset[ .panel[.panel-name[Arguments] ```r pivot_longer(data, cols, names_to, values_to) ``` `data` is a data frame to pivot. `cols` are the columns to pivot into longer format. `names_to` is a string specifying the name of the column to create from the data stored in the column names of `data`. `values_to` is a string specifying the name of the column to create from the data stored in the cell values. ] .panel[.panel-name[Example] ```r enrollment %>% pivot_longer(cols = c(`2020`, `2021`), names_to = "year", values_to = "enrollment") ``` .pull-left[ **Output: A longer data frame** ``` ## # A tibble: 6 x 3 ## university year enrollment ## <chr> <chr> <dbl> ## 1 UO 2020 21800 ## 2 UO 2021 22298 ## 3 OSU 2020 33359 ## 4 OSU 2021 34108 ## 5 PSU 2020 26012 ## 6 PSU 2021 23181 ``` ] .pull-right[ **Notes** + We had to put the variable names `2020` and `2021` in backticks because column names are normally not allowed to start with numbers + `year` and `enrollment` do not exist in `enrollment` so we put their names in quotes. ] ] ] --- class: split-60 background-image: url(images/hex/tidyr.png) background-position: 90% 5% background-size: 10% # `pivot_wider()` Below is a different data set (`enrollment2`) that needs to be reshaped to a wider format. A single observation is a `university` in a `year`, but each observation is spread across two rows. *** .column[ <br> .content[.center[ <br><br><br><br><br><br><br><br><br><br> ```r enrollment2 ``` ``` ## # A tibble: 12 x 4 ## university year type count ## <chr> <dbl> <chr> <dbl> ## 1 UO 2020 enrollment 21800 ## 2 UO 2020 faculty 1926 ## 3 UO 2021 enrollment 22298 ## 4 UO 2021 faculty 1949 ## 5 OSU 2020 enrollment 33359 ## 6 OSU 2020 faculty 4730 ## 7 OSU 2021 enrollment 34108 ## 8 OSU 2021 faculty 4798 ## 9 PSU 2020 enrollment 26012 ## 10 PSU 2020 faculty 1694 ## 11 PSU 2021 enrollment 23181 ## 12 PSU 2021 faculty 1690 ``` ]]] -- .column[ <br><br> .content[ <br><br><br><br><br><br><br><br><br><br> To tidy this up, we need two pieces of information: -The column to take variable names from (`type`) -The column to take values from (`count`) ]] --- background-image: url(images/hex/tidyr.png) background-position: 90% 5% background-size: 10% # `pivot_wider()` .panelset[ .panel[.panel-name[Arguments] ```r pivot_wider(data, names_from, values_from) ``` `data` is a data frame to pivot. `names_from` is the column (or columns) to get the name(s) of the output column(s) from. `values_from` is the column (or columns) to get the cell values from. ] .panel[.panel-name[Example] ```r enrollment2 %>% pivot_wider(names_from = type, values_from = count) ``` ``` ## # A tibble: 6 x 4 ## university year enrollment faculty ## <chr> <dbl> <dbl> <dbl> ## 1 UO 2020 21800 1926 ## 2 UO 2021 22298 1949 ## 3 OSU 2020 33359 4730 ## 4 OSU 2021 34108 4798 ## 5 PSU 2020 26012 1694 ## 6 PSU 2021 23181 1690 ``` ] ] --- class: yourturn # Your turn 1 <div class="countdown" id="timer_632d31e4" style="right:0;bottom:0;" data-warnwhen="0"> <code class="countdown-time"><span class="countdown-digits minutes">04</span><span class="countdown-digits colon">:</span><span class="countdown-digits seconds">00</span></code> </div> 1. Use `pivot_longer()` to tidy `table4a` (included as part of the `tidyr` package). 1. Use `pivot_wider()` to tidy `table2` (included as part of the `tidyr` package). --- class: solution # Solution .panelset[ .panel[.panel-name[Q1] ```r table4a %>% pivot_longer(cols = c(`1999`, `2000`), names_to = "year", values_to = "cases") ``` ``` ## # A tibble: 6 x 3 ## country year cases ## <chr> <chr> <int> ## 1 Afghanistan 1999 745 ## 2 Afghanistan 2000 2666 ## 3 Brazil 1999 37737 ## 4 Brazil 2000 80488 ## 5 China 1999 212258 ## 6 China 2000 213766 ``` ] .panel[.panel-name[Q2] ```r table2 %>% pivot_wider(names_from = type, values_from = count) ``` ``` ## # A tibble: 6 x 4 ## country year cases population ## <chr> <int> <int> <int> ## 1 Afghanistan 1999 745 19987071 ## 2 Afghanistan 2000 2666 20595360 ## 3 Brazil 1999 37737 172006362 ## 4 Brazil 2000 80488 174504898 ## 5 China 1999 212258 1272915272 ## 6 China 2000 213766 1280428583 ``` ] ] --- class: inverse, center, middle # Q & A <div class="countdown" id="timer_632d30ea" style="right:0;bottom:0;" data-warnwhen="0"> <code class="countdown-time"><span class="countdown-digits minutes">05</span><span class="countdown-digits colon">:</span><span class="countdown-digits seconds">00</span></code> </div> --- class: inverse, center, middle # Break! <div class="countdown" id="timer_632d30ca" style="right:0;bottom:0;" data-warnwhen="0"> <code class="countdown-time"><span class="countdown-digits minutes">05</span><span class="countdown-digits colon">:</span><span class="countdown-digits seconds">00</span></code> </div>